Jugando con internet acabo de descubrir mozilla seamonkey. Miré a ver que era y ponía que es una especie de navegador, correo y editor de html todo junto.
Lo he instalado y me ha decepcionado un poco. Es casi exactamente lo que antes era netscape, que venía con navegador, composer, etc. No quiero decir que el programa esté mal, sino simplemente que es lo mismo que el antiguo netscape, pero con otro nombre.
Seguiré con el firefox y el thunderbird, que me gustaron bastante más nada más instalarlos.
En cuanto a editor de html, tradicionalmente he utilizado el netscape composer. Sin embargo, hace poco, que empecé a meter algun java script ajeno, me empezó a hacer cosas raras. Y desde luego, no he conseguido que se trague una página php sin descuajeringarla, a pesar del que el 90% de la página es html. Por eso me he acabado cambiando a dreamweaber y de momento estoy contento con él. No uso todo lo que tiene, puesto que mis páginas son muy sencillitas, sólo html y algo mínimo de php en alguna ocasión, y algún javascript ajeno que inserto (contadores de estadísticas, google adsense, etc), unas pruebas con css, pero me hace bien lo que quiero que haga. Sobre todo no me descuajeringa una página cuando su extensión es php.
28 julio 2006
Crear .exe de java
Aunque la forma normal de hacer un programa java es generar un fichero jar, su ejecución puede ser compleja para un usuario que no conozca java. Por ello, entregar una aplicación java a un usuario normalito de ordenador suele requerir entregar también un .bat de arranque, que revise si existe máquina virtual, que ponga cosas como el classpath, etc, etc.
Hay utilidades que permiten pasar nuestro .jar a un fichero .exe normal de windows, de forma que a un usuario no programador le resulte más fácil el arranque.
Algunas de estas utilidades, como JSmooth, simplemente crean un pequeño exe que arranca la aplicación, pero necesitan que la máquina virtual esté instalada.
gcj sí crea un verdadero ejecutable, pero gcj está pensado para el entorno de gnu, por lo que para ejecutarlo en windows es necesario instalar previamente el cygwin. gcj venga mejor posiblemente para usuarios de linux/unix.
java2exe (ahora JexePack) también permite generar .exe, pero es una aplicación de pago.
Algunos IDE, como JBuilder, también permiten generar el exe.
De todas formas, no he probado ninguno de ellos. De momento no tengo ninguna necesidad especial de generar .exe. Además, pienso que se pierde un poco la filosofía de java, que es que el "ejecutable" se pueda ejecutar en cualquier sistema operativo. Tampoco suelo hacer aplicaciones para usuarios no programadores.
Hay utilidades que permiten pasar nuestro .jar a un fichero .exe normal de windows, de forma que a un usuario no programador le resulte más fácil el arranque.
Algunas de estas utilidades, como JSmooth, simplemente crean un pequeño exe que arranca la aplicación, pero necesitan que la máquina virtual esté instalada.
gcj sí crea un verdadero ejecutable, pero gcj está pensado para el entorno de gnu, por lo que para ejecutarlo en windows es necesario instalar previamente el cygwin. gcj venga mejor posiblemente para usuarios de linux/unix.
java2exe (ahora JexePack) también permite generar .exe, pero es una aplicación de pago.
Algunos IDE, como JBuilder, también permiten generar el exe.
De todas formas, no he probado ninguno de ellos. De momento no tengo ninguna necesidad especial de generar .exe. Además, pienso que se pierde un poco la filosofía de java, que es que el "ejecutable" se pueda ejecutar en cualquier sistema operativo. Tampoco suelo hacer aplicaciones para usuarios no programadores.
27 julio 2006
Cambiar el icono de la taza de café en java
La forma normal de cambiar el icono de la taza de café en java en una aplicación consiste en llamar al método setIconImage() del JFrame principal de la aplicación. Luego, el resto de JDialog de la aplicación deben ser hijos, nietos o biznietos de este JFrame, heredando así su icono. Puedes ver más detalles de este cambio de icono.
Sin embargo, ayer un compañero de trabajo encontró una forma más bruta de hacerlo, de forma que queda cambiado para todas las aplicaciones java de nuestro ordenador (salvo que ellas lo cambien de forma expresa dentro).
Este método de fuerza bruta consiste en buscar dentro de nuestra instalación de java los ficheros rt.jar y awt.dll, que contienen dentro dicho icono de la taza de café y cambiarlo por otro. En Cambiar el icono de la taza de café están los detalles.
Sin embargo, ayer un compañero de trabajo encontró una forma más bruta de hacerlo, de forma que queda cambiado para todas las aplicaciones java de nuestro ordenador (salvo que ellas lo cambien de forma expresa dentro).
Este método de fuerza bruta consiste en buscar dentro de nuestra instalación de java los ficheros rt.jar y awt.dll, que contienen dentro dicho icono de la taza de café y cambiarlo por otro. En Cambiar el icono de la taza de café están los detalles.
25 julio 2006
Dos programas opuestos
Aquí un par de programitas para java que pueden ser más o menos útiles y que sirven para lo contrario.
El primero es un "descompilador" de java. El DJ Java Decompiler es un programita que dándole los ficheros .class es capaz de sacarnos los fuentes .java. Tiene interface gráfica y es gratis.
El otro programa, en realidad son varios, son los ofuscadores de código java. Precisamente para evitar que nuestros programas java puedan ser "descompilados", existen estos ofuscadores. Básicamente lo que hacen es cambiar los nombres de clases, métodos y variables por nombres crípticos. El programa .class puedes descompilarse igualmente, pero no es lo mismo intuir que el método setNombre(String nombre) de la clase Persona mete el nombre de la persona en la clase Persona, que intuir qué demonios hace afaewser(String afew) de la clase Xdañsiñwe. Supuestamente, además de ofuscar y ya puestos a tocar el jar, la mayoría de ellos llevan a cabo labores de optimización, tratando de reducir el jar lo máximo posible, eliminando código innecesario, variables no usadas, métodos no usados, etc. De hecho, la ofuscación de código es más bien un "efecto secundario" de este proceso. Para reducir el tamaño del jar, no hay nada como llamar a las clases, métodos y variables con nombres lo más cortos posibles. No he probado ninguno, pero por lo que he leido es lo que intuyo que hacen...
ProGuard es un ofuscador gratuito y en la misma página tienes un listado de otros ofuscadores de código.
El primero es un "descompilador" de java. El DJ Java Decompiler es un programita que dándole los ficheros .class es capaz de sacarnos los fuentes .java. Tiene interface gráfica y es gratis.
El otro programa, en realidad son varios, son los ofuscadores de código java. Precisamente para evitar que nuestros programas java puedan ser "descompilados", existen estos ofuscadores. Básicamente lo que hacen es cambiar los nombres de clases, métodos y variables por nombres crípticos. El programa .class puedes descompilarse igualmente, pero no es lo mismo intuir que el método setNombre(String nombre) de la clase Persona mete el nombre de la persona en la clase Persona, que intuir qué demonios hace afaewser(String afew) de la clase Xdañsiñwe. Supuestamente, además de ofuscar y ya puestos a tocar el jar, la mayoría de ellos llevan a cabo labores de optimización, tratando de reducir el jar lo máximo posible, eliminando código innecesario, variables no usadas, métodos no usados, etc. De hecho, la ofuscación de código es más bien un "efecto secundario" de este proceso. Para reducir el tamaño del jar, no hay nada como llamar a las clases, métodos y variables con nombres lo más cortos posibles. No he probado ninguno, pero por lo que he leido es lo que intuyo que hacen...
ProGuard es un ofuscador gratuito y en la misma página tienes un listado de otros ofuscadores de código.
21 julio 2006
Método toString() de Element de org.w3c.dom
Me he tropezado con un pequeño problemilla que cuento aquí por si a alguien más le pasa lo mismo.
Resulta que trabajando con la versión 1.4 de java, cuando tengo un Document correspondiente a un fichero xml guardado en memoria, haciendo toString() del Element raiz del Document, me devuelve un String con el contenido del fichero xml.
Sin embargo, ¡sorpresa!, en la versión 1.5 de java este método toString() ya no devuelve el String el formato xml, sino que devuelve una cosa rara, cortita, que no vale.
En Bug ID: 6181019 REGRESSION: org.w3c.dom.Element.toString() no longer returns the xml document: "toString" está comentado este problema con más detalle.
Resulta que trabajando con la versión 1.4 de java, cuando tengo un Document correspondiente a un fichero xml guardado en memoria, haciendo toString() del Element raiz del Document, me devuelve un String con el contenido del fichero xml.
Sin embargo, ¡sorpresa!, en la versión 1.5 de java este método toString() ya no devuelve el String el formato xml, sino que devuelve una cosa rara, cortita, que no vale.
En Bug ID: 6181019 REGRESSION: org.w3c.dom.Element.toString() no longer returns the xml document: "toString" está comentado este problema con más detalle.
Contar líneas de código
Hay una cosa que descubrí hace ya bastante tiempo, pero que me llamó mucho la atención por su simplicidad, y es el cómo se pueden contar las líneas de código de un programa de una forma simple.
En su momento, cuando me ví en la necesidad de contar las líneas de código que habíamos hecho en el trabajo, y de esto hace mucho y no había las herramientas que hay ahora o, al menos, no se encontraban de forma gratuita en la red, me puse a pensar en ello y buscar por internet.
Lo de contar líneas tal cual (contar retornos de carro) me parecía poco fiable. Si alguien deja muchas líneas en blanco, no hace muchas líneas de código, pero se cuentan como tales. Los comentarios también contarían como líneas de código. Si alguien abre las llaves "{" en una nueva línea
public void funcion ()
{
...
hace más líneas de código que uno que lo pone todo seguido
public void funcion () {
...
Investigando por internet, encontré la forma muy aproximada y sencilla de hacerlo. ¡¡Basta con contar los punto y coma ";" del código!!
Como cada línea de código acaba en punto y coma (En C, C++, java y otros muchos lenguajes) esto nos da una aproximación muy buena y simple del número de líneas de código.
Además, si alguien es vago como yo y no quiere demasiada precisión en la medida, basta con encadenar unos comandos de unix/linux para contar algo parecido al número de puntos y coma
$ cat `find . -name *.java` | egrep ";" | wc -l
La primera parte saca un listado por pantalla (cat) de todos los ficheros .java que encuentre del directorio actual hacia abajo.
La segunda parte, filtra (egrep) para que en el listado sólo salgan las líneas que contienen al menos un punto y coma.
La tercera parte, cuenta (wc) las líneas del listado anterior.
El resultado es el número total de líneas de los ficheros .java que contienen al menos un punto y coma, es decir, una aproximación más o menos buena del número de líneas de código.
De todas formas, alguien que sepa un poco más de linux seguro que encuentra la forma de contar el número de ; de una forma también sencilla ...
En su momento, cuando me ví en la necesidad de contar las líneas de código que habíamos hecho en el trabajo, y de esto hace mucho y no había las herramientas que hay ahora o, al menos, no se encontraban de forma gratuita en la red, me puse a pensar en ello y buscar por internet.
Lo de contar líneas tal cual (contar retornos de carro) me parecía poco fiable. Si alguien deja muchas líneas en blanco, no hace muchas líneas de código, pero se cuentan como tales. Los comentarios también contarían como líneas de código. Si alguien abre las llaves "{" en una nueva línea
public void funcion ()
{
...
hace más líneas de código que uno que lo pone todo seguido
public void funcion () {
...
Investigando por internet, encontré la forma muy aproximada y sencilla de hacerlo. ¡¡Basta con contar los punto y coma ";" del código!!
Como cada línea de código acaba en punto y coma (En C, C++, java y otros muchos lenguajes) esto nos da una aproximación muy buena y simple del número de líneas de código.
Además, si alguien es vago como yo y no quiere demasiada precisión en la medida, basta con encadenar unos comandos de unix/linux para contar algo parecido al número de puntos y coma
$ cat `find . -name *.java` | egrep ";" | wc -l
La primera parte saca un listado por pantalla (cat) de todos los ficheros .java que encuentre del directorio actual hacia abajo.
La segunda parte, filtra (egrep) para que en el listado sólo salgan las líneas que contienen al menos un punto y coma.
La tercera parte, cuenta (wc) las líneas del listado anterior.
El resultado es el número total de líneas de los ficheros .java que contienen al menos un punto y coma, es decir, una aproximación más o menos buena del número de líneas de código.
De todas formas, alguien que sepa un poco más de linux seguro que encuentra la forma de contar el número de ; de una forma también sencilla ...
Tutorial C y C++ , Programación de sockets con C y linux
Veo en Tutorial C y C++ , Programación de sockets con C y linux que han puesto uno de mis tutoriales en un marco y justo encima han puesto una cabecera de ellos.
El marco es directamente mi página, no es una copia, y en la cabecera ponen la página original. En fin, me parece todo bien y correcto, pero me ha llamado mucho la atención el verlo ...
El marco es directamente mi página, no es una copia, y en la cabecera ponen la página original. En fin, me parece todo bien y correcto, pero me ha llamado mucho la atención el verlo ...
17 julio 2006
El PageRank de google está cabra
Acabo de ver que después de cuatro meses de mis apuntes de programación. por fin tiene un PageRank. Le dieron uno de cero al poco de crear la página/dominio. Ahora tiene uno de 4, que es más o menos lo que tenía mi antigua página www.geocities.com/chuidiang.
Sin embargo, veo que el page rank actual está un poco tonto.
Mi diario de correr y bicicleta tiene un pagerank de 3. Si miro, según google, las páginas que enlazan a él, no hay ninguna. Tampoco tiene apenas visitas. Sin embargo, este diario de programación tiene sólo un pagerank de 2. Hay varias páginas que enlazan a él (según google) aparte de la mía y además tiene unas cuantas visitas diarias.
¿Cómo es posible esto?.
También hay otro mito que no sé si es real. Supuestamente con un pagerank más elevado tus páginas salen más arriba en los buscadores. Sin embargo, desde que mis apuntes de programación han pasado de pagerank 0 a pakerank 4 (el viernes o el sábado pasado), no he notado ningún cambio en el número de visitas.
Sin embargo, de vez en cuando sí noto cambios bruscos que duran temporadas largas de vez en cuando. Por ejemplo, el número de visitas se ha reducido casi a la mitad, de forma progresiva, desde mediados de Junio sin razón aparente (ver gráfico).
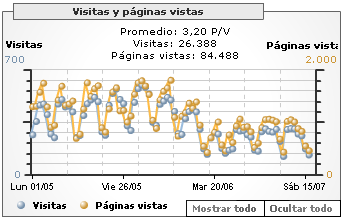
Sin embargo, veo que el page rank actual está un poco tonto.
Mi diario de correr y bicicleta tiene un pagerank de 3. Si miro, según google, las páginas que enlazan a él, no hay ninguna. Tampoco tiene apenas visitas. Sin embargo, este diario de programación tiene sólo un pagerank de 2. Hay varias páginas que enlazan a él (según google) aparte de la mía y además tiene unas cuantas visitas diarias.
¿Cómo es posible esto?.
También hay otro mito que no sé si es real. Supuestamente con un pagerank más elevado tus páginas salen más arriba en los buscadores. Sin embargo, desde que mis apuntes de programación han pasado de pagerank 0 a pakerank 4 (el viernes o el sábado pasado), no he notado ningún cambio en el número de visitas.
Sin embargo, de vez en cuando sí noto cambios bruscos que duran temporadas largas de vez en cuando. Por ejemplo, el número de visitas se ha reducido casi a la mitad, de forma progresiva, desde mediados de Junio sin razón aparente (ver gráfico).

13 julio 2006
Ficheros KK
En todo proyecto informático que se precie hay uno o más ficheros "kk", que no sirven para nada, que nadie usa, pero que si se te ocurre borrar el proyecto deja de funcionar.
También suele haber varias versiones de ejecutable, cuyos ficheros se llaman así ejecutable_bueno.exe, ejecutable_nuevo.exe, ejecutable_hoy.exe, ejecutable_ultimo.exe. Está claro que esta nomenclatura de nombres es la más adecuada para saber cual es el que hay que arrancar, en función de que se quiera el bueno, el nuevo, el de hoy o el último.
También suele haber varias versiones antiguas, etiquetads ejecutable_antiguo.exe, ejecutable.exe.bak, ejecutable.exe.old, ejecutable_viejo.exe. De esta forma también es fácil saber qué se debe recuperar, según se quiera el old, el viejo, el bak o el antiguo.
Rizando el rizo, a veces también hay líneas de código que nunca se llaman, ni poniendo un breakpoint con el debugger en ellas, ni System.out, ni printf, ni de ninguna manera, pero ¡Ay de tí como se te ocurra borrarlas!. El ejecutable dejará de funcionar.
También suele haber varias versiones de ejecutable, cuyos ficheros se llaman así ejecutable_bueno.exe, ejecutable_nuevo.exe, ejecutable_hoy.exe, ejecutable_ultimo.exe. Está claro que esta nomenclatura de nombres es la más adecuada para saber cual es el que hay que arrancar, en función de que se quiera el bueno, el nuevo, el de hoy o el último.
También suele haber varias versiones antiguas, etiquetads ejecutable_antiguo.exe, ejecutable.exe.bak, ejecutable.exe.old, ejecutable_viejo.exe. De esta forma también es fácil saber qué se debe recuperar, según se quiera el old, el viejo, el bak o el antiguo.
Rizando el rizo, a veces también hay líneas de código que nunca se llaman, ni poniendo un breakpoint con el debugger en ellas, ni System.out, ni printf, ni de ninguna manera, pero ¡Ay de tí como se te ocurra borrarlas!. El ejecutable dejará de funcionar.
07 julio 2006
Más sobre el patrón Decorador
Acabo de terminar mi primer cacho de programa usando el patrón Decorador como comenté en el post anterior.
Una primera ventaja que le veo, en mi caso concreto, es que puedo hacer todo el código sin necesidad de la base de datos y probarlo. Mi modelo de datos va en memoria implementando una interface, mis clases de ventanas y demás sólo ven la interface. Mis clases de mis librerías reutilizables sólo ven la interface, así que puedo usarlas tal cual sin tocar nada en ellas, sin necesidad de hererdar ni de configurarlas de ninguna manera.
Luego, hago el decorador del modelo que se encarga de la base de datos. Dentro de él meto el modelo de datos e implemento todos los métodos simplemente para que se redirijan al modelo interno. Con esto todo sigue funcionando igual que antes, sin base de datos.
Ahora sólo me queda, poco a poco, ir modificando los métodos del decorador para que hagan su trabajo en la base de datos.
Otra ventaja adicional que le veo es que todo lo de base de datos (las sql, la conexion, etc, etc) queda encapsulado en una única clase.
La verdad es que la experiencia me ha gustado bastante y pienso repetir en adelante.
Una primera ventaja que le veo, en mi caso concreto, es que puedo hacer todo el código sin necesidad de la base de datos y probarlo. Mi modelo de datos va en memoria implementando una interface, mis clases de ventanas y demás sólo ven la interface. Mis clases de mis librerías reutilizables sólo ven la interface, así que puedo usarlas tal cual sin tocar nada en ellas, sin necesidad de hererdar ni de configurarlas de ninguna manera.
Luego, hago el decorador del modelo que se encarga de la base de datos. Dentro de él meto el modelo de datos e implemento todos los métodos simplemente para que se redirijan al modelo interno. Con esto todo sigue funcionando igual que antes, sin base de datos.
Ahora sólo me queda, poco a poco, ir modificando los métodos del decorador para que hagan su trabajo en la base de datos.
Otra ventaja adicional que le veo es que todo lo de base de datos (las sql, la conexion, etc, etc) queda encapsulado en una única clase.
La verdad es que la experiencia me ha gustado bastante y pienso repetir en adelante.
05 julio 2006
Posibilidad para el patrón Decorador
Estoy experimentando con el patrón Decorador y de momento parece que tiene buena pinta.
Me explico. Es bastante habitual que tenga que hacer alguna aplicación con unas ventanas para mostrar datos recogidos de una base de datos. Desde dichas ventanas debe además poder modificarse los datos en base de datos. Los típicos añadir, borrar y editar.
Mi forma habitual de hacer esto era con el patrón Observador. Hago una clase que llamo modelo de datos en la que guardo los datos de la base de datos después de haberlos leido. A esta clase le pongo un mecanismo de suscripción, de forma que otras clases puedan enterarse cuando se modifican los datos.
Hago otra clase que se encarga de leer la base de datos y rellenar el modelo de datos. Tiene además los métodos para añadir, modificar y borrar elementos de base de datos.
Las ventanas son clases que están suscritas al modelo de datos, de forma que cuando el modelo de datos se rellena de datos, automáticamente las ventanas los muestran. Algo similar al DefaultTableModel de java y el JTable.
Los botones de las ventanas que permiten modificar los datos los suelo hacer que actuen directamente con la clase que se encarga de la base de datos. Si unos de estos botones debe añadir, borrar o modificar algo, lo hace contra la clase de base de datos. Esta se encarga de hacer la modificación en base de datos y si tiene exito, refleja el cambio en el modelo. Este a su vez por medio del patrón observador avisa a la ventana para que refleje el cambio.
Todo este es el mecanismo que uso habitualmente, pero no me acaba de convencer porque acaba todo entremezclado. Los botones, que son interface de usuario, deben ver a la clase de base de datos y esta a su vez ve al modelo de datos. Tengo botones ya hechos que hacen las tareas habituales de añadir, borrar y modificar elementos de una lista, pero siempre tengo que heredar de ellos o instanciarlos pasándoles la clase de base de datos y "capando" su comportamiento de actuar sobre le modelo directamente.
Ahora estoy intentando aplicar el patrón Decorador. Consiste básicamente en hacer que la clase de modelo de datos y la clase de base de datos cumplan la misma interface y puedan intercambiarse. Ambas tienen métodos añade(), borra() y modifica(). La clase de base de datos además admite que se le pase el modelo de datos.
El método añadir(), por ejemplo, en la clase de base de datos, inserta en base de datos y si la inserción tiene éxito, llama al añadir() del modelo de datos.
Tanto el modelo de datos como la clase de base de datos implementan un patrón observador, para notificar cambios en los datos. La de modelo de datos es normal. La clase de base de datos se suscribe al modelo de datos y notifica cuando notifique este. De esta forma, cuando la clase de base de datos añade() un dato, lo mete en base de datos y luego en el modelo. El modelo avisa a la clase de base de datos y esta a sus suscriptores, que serán las ventanas.
Al hacer que ambas clases implementen la misma interface, a las ventanas puedo pasarles indistintamente una u otra. Las ventanas y los botones actuarían directamente sobre la interface, con lo que no saben si lo están haciendo contra base de datos o contra el modelo de datos. Las ventanas se refrescarán también correctamente independientemente de qué modelo se les pase.
Esto tiene otra ventaja adicional, y es en el borrado. Habitualmente los modelos de java como TableModel, avisan del borrado después de haber borrado. Con mi antiguo mecanismo de suscripción, no podía obtener el elemento borrado para borraren la base de datos, únicamente sabía qué fila se había borrado, pero no podía obtener el elemento borrado, ni su clave en la base de datos. Con este nuevo mecanismo de patrón Decorador, me avisan cuando se quiere borrar, con lo que puedo borrar de base de datos, luego del modelo y luego se refresca la vista.
En fin, lo poco que voy probando va teniendo buena pinta y muchas ventajas respecto a mi antiguo mecanismo. En algún momento haré un pequeño tutorial para mi página en la que se haga una tabla con añadir, borrar y modificar de una base de datos usando este patrón.
Me explico. Es bastante habitual que tenga que hacer alguna aplicación con unas ventanas para mostrar datos recogidos de una base de datos. Desde dichas ventanas debe además poder modificarse los datos en base de datos. Los típicos añadir, borrar y editar.
Mi forma habitual de hacer esto era con el patrón Observador. Hago una clase que llamo modelo de datos en la que guardo los datos de la base de datos después de haberlos leido. A esta clase le pongo un mecanismo de suscripción, de forma que otras clases puedan enterarse cuando se modifican los datos.
Hago otra clase que se encarga de leer la base de datos y rellenar el modelo de datos. Tiene además los métodos para añadir, modificar y borrar elementos de base de datos.
Las ventanas son clases que están suscritas al modelo de datos, de forma que cuando el modelo de datos se rellena de datos, automáticamente las ventanas los muestran. Algo similar al DefaultTableModel de java y el JTable.
Los botones de las ventanas que permiten modificar los datos los suelo hacer que actuen directamente con la clase que se encarga de la base de datos. Si unos de estos botones debe añadir, borrar o modificar algo, lo hace contra la clase de base de datos. Esta se encarga de hacer la modificación en base de datos y si tiene exito, refleja el cambio en el modelo. Este a su vez por medio del patrón observador avisa a la ventana para que refleje el cambio.
Todo este es el mecanismo que uso habitualmente, pero no me acaba de convencer porque acaba todo entremezclado. Los botones, que son interface de usuario, deben ver a la clase de base de datos y esta a su vez ve al modelo de datos. Tengo botones ya hechos que hacen las tareas habituales de añadir, borrar y modificar elementos de una lista, pero siempre tengo que heredar de ellos o instanciarlos pasándoles la clase de base de datos y "capando" su comportamiento de actuar sobre le modelo directamente.
Ahora estoy intentando aplicar el patrón Decorador. Consiste básicamente en hacer que la clase de modelo de datos y la clase de base de datos cumplan la misma interface y puedan intercambiarse. Ambas tienen métodos añade(), borra() y modifica(). La clase de base de datos además admite que se le pase el modelo de datos.
El método añadir(), por ejemplo, en la clase de base de datos, inserta en base de datos y si la inserción tiene éxito, llama al añadir() del modelo de datos.
Tanto el modelo de datos como la clase de base de datos implementan un patrón observador, para notificar cambios en los datos. La de modelo de datos es normal. La clase de base de datos se suscribe al modelo de datos y notifica cuando notifique este. De esta forma, cuando la clase de base de datos añade() un dato, lo mete en base de datos y luego en el modelo. El modelo avisa a la clase de base de datos y esta a sus suscriptores, que serán las ventanas.
Al hacer que ambas clases implementen la misma interface, a las ventanas puedo pasarles indistintamente una u otra. Las ventanas y los botones actuarían directamente sobre la interface, con lo que no saben si lo están haciendo contra base de datos o contra el modelo de datos. Las ventanas se refrescarán también correctamente independientemente de qué modelo se les pase.
Esto tiene otra ventaja adicional, y es en el borrado. Habitualmente los modelos de java como TableModel, avisan del borrado después de haber borrado. Con mi antiguo mecanismo de suscripción, no podía obtener el elemento borrado para borraren la base de datos, únicamente sabía qué fila se había borrado, pero no podía obtener el elemento borrado, ni su clave en la base de datos. Con este nuevo mecanismo de patrón Decorador, me avisan cuando se quiere borrar, con lo que puedo borrar de base de datos, luego del modelo y luego se refresca la vista.
En fin, lo poco que voy probando va teniendo buena pinta y muchas ventajas respecto a mi antiguo mecanismo. En algún momento haré un pequeño tutorial para mi página en la que se haga una tabla con añadir, borrar y modificar de una base de datos usando este patrón.
29 junio 2006
Echo de menos programar mal
Últimamente ando un poco deprimido con esto de la programación. Llevo muchos años programando y mi forma de programar ha ido evolucionando mucho, se supone que para mejor.
Al principio hacía mi código rápido. Mis clases eran gigantes y muy poco reutilizables. Apenas usaba herencias, prácticamente nunca el polimorfismo y nunca había oido hablar de patrones de diseño. Mi objetivo era hacer el código rápido y que funcionara.
Luego aprendí a usar el polimorfismo, leí sobre patrones, las clases deben ser pequeñas, el código debe ser reutilizable, hay que comentar, etc, etc.
Ahora programa tratando de seguir todas estas cosas. Cualquier programa que hago se llena de clases separaditas, algunas de ellas siempre acabo reusándolas en otro sitio. Me llevo clases de estas a "librerías" que clases para usar en otrs proyectos. Mi código tira mucho de esas "librerías" que me he ido haciendo con el tiempo. Uso los patrones, el polimorfismo. Supuestamente, todo lo más mejor que soy capaz de hacerlo.
Sin embargo, hecho de menos los viejos tiempos. Antes programar era divertido. Ahora se convierte casi en una tortura. Cuando hago algo o modifico algo hecho, tengo que emepezar a revisar las clases de las librerías, soy incapaz de hacer algo una clase grande o un método largo, así que hago muchas clases y métodos. Cuando una cosa parece que puede ser reutilizable más adelante, la hago un poco mejor para llevármela a la librería, etc, etc.
Para un mismo programa, ahora hago muchísmimas menos líneas de código, pero echo bastate tiempo en pensarlas, rebuscar por la librerías, por las clases ya hechas, pasando de una interface a la clase que la implementa que simplemente acaba llamando a un método de otra clase que a su vez...
Echo de menos los tiempos en que programar era liarse a echar lineas de código sin más, aunque no fuera la forma más eficiente.
Al principio hacía mi código rápido. Mis clases eran gigantes y muy poco reutilizables. Apenas usaba herencias, prácticamente nunca el polimorfismo y nunca había oido hablar de patrones de diseño. Mi objetivo era hacer el código rápido y que funcionara.
Luego aprendí a usar el polimorfismo, leí sobre patrones, las clases deben ser pequeñas, el código debe ser reutilizable, hay que comentar, etc, etc.
Ahora programa tratando de seguir todas estas cosas. Cualquier programa que hago se llena de clases separaditas, algunas de ellas siempre acabo reusándolas en otro sitio. Me llevo clases de estas a "librerías" que clases para usar en otrs proyectos. Mi código tira mucho de esas "librerías" que me he ido haciendo con el tiempo. Uso los patrones, el polimorfismo. Supuestamente, todo lo más mejor que soy capaz de hacerlo.
Sin embargo, hecho de menos los viejos tiempos. Antes programar era divertido. Ahora se convierte casi en una tortura. Cuando hago algo o modifico algo hecho, tengo que emepezar a revisar las clases de las librerías, soy incapaz de hacer algo una clase grande o un método largo, así que hago muchas clases y métodos. Cuando una cosa parece que puede ser reutilizable más adelante, la hago un poco mejor para llevármela a la librería, etc, etc.
Para un mismo programa, ahora hago muchísmimas menos líneas de código, pero echo bastate tiempo en pensarlas, rebuscar por la librerías, por las clases ya hechas, pasando de una interface a la clase que la implementa que simplemente acaba llamando a un método de otra clase que a su vez...
Echo de menos los tiempos en que programar era liarse a echar lineas de código sin más, aunque no fuera la forma más eficiente.
28 junio 2006
maven
En el trabajo ya he metido un par de proyectos con maven.
Con el tiempo hemos desarrollado varias librerías en java. Una de comunicaciones (sockets y rmi), otra con algoritmos matemáticos, otra con componentes de interface de usuario, para ventanitas con acceso a base de datos, etc, etc.
He creado proyectos maven para los fuentes de cada una de estas librerías. En un servidor he montado un repositorio de jar accesible para todo el mundo a través de ftp. Con maven, he compilado estas librerías y metido los jar en el respositorio común.
En dos proyectos que están ahora en marcha, los he modificado para que funcionen con maven. He puesto las dependencias correspondientes a log4j y demás librerías standard, además de las dependencias de nuestras librerías propias. Todo ha funcionado correctamente. Al compilar por primera vez estos proyectos con maven, se ha ido a internet y a mi repositorio de jars a buscar las librerías indicadas, se las ha descargado y todo bien.
Me quedan sin embargo dos pequeñas pegas que solucionaré jugando un poco.
Por un lado, si modifico un jar dentro del repositorio de jars, no sé si los proyectos que lo utilizan se enteran y se bajan la nueva versión (a la que no he numerado como nueva versión). Creo que poniendo lo que maven llama versión SNAPSHOT, sí lo haría. De todas formas, la primera prueba que he hecho con esto no me acaba de convencer.
Por otro lado, todo el tema de integración con los IDE. Maven tiene estos comandos
mvn idea:idea
mvn eclipse:eclipse
que generan los proyectos para Idea y para eclipse. Para el primero funciona todo perfecto. Sin embargo, para eclipse parace que el tema funciona peor. No me gusta cómo se monta el proyecto en eclipse, sobre todo si es un proyecto maven con subproyectos debajo.
Hay además un plugin de eclipse para poder utilizar maven desde el ide. Lo he instalado una vez y me ha ido bien, pero ya no puedo tocar en dependencias el proyecto como a mi me gustaría. Un compañero mio ha instalado el mismo plugin y no ha podido volver a abrir eclipse. Le da un error en el inicio, antes de abrir nada y de ahí no sale, ni desinstalando el plugin a mano (borrándolo del directorio plugins).
En fin, con eclipse parece que ese plugin no es buena cosa, aunque seguiré en ello.
Con el tiempo hemos desarrollado varias librerías en java. Una de comunicaciones (sockets y rmi), otra con algoritmos matemáticos, otra con componentes de interface de usuario, para ventanitas con acceso a base de datos, etc, etc.
He creado proyectos maven para los fuentes de cada una de estas librerías. En un servidor he montado un repositorio de jar accesible para todo el mundo a través de ftp. Con maven, he compilado estas librerías y metido los jar en el respositorio común.
En dos proyectos que están ahora en marcha, los he modificado para que funcionen con maven. He puesto las dependencias correspondientes a log4j y demás librerías standard, además de las dependencias de nuestras librerías propias. Todo ha funcionado correctamente. Al compilar por primera vez estos proyectos con maven, se ha ido a internet y a mi repositorio de jars a buscar las librerías indicadas, se las ha descargado y todo bien.
Me quedan sin embargo dos pequeñas pegas que solucionaré jugando un poco.
Por un lado, si modifico un jar dentro del repositorio de jars, no sé si los proyectos que lo utilizan se enteran y se bajan la nueva versión (a la que no he numerado como nueva versión). Creo que poniendo lo que maven llama versión SNAPSHOT, sí lo haría. De todas formas, la primera prueba que he hecho con esto no me acaba de convencer.
Por otro lado, todo el tema de integración con los IDE. Maven tiene estos comandos
mvn idea:idea
mvn eclipse:eclipse
que generan los proyectos para Idea y para eclipse. Para el primero funciona todo perfecto. Sin embargo, para eclipse parace que el tema funciona peor. No me gusta cómo se monta el proyecto en eclipse, sobre todo si es un proyecto maven con subproyectos debajo.
Hay además un plugin de eclipse para poder utilizar maven desde el ide. Lo he instalado una vez y me ha ido bien, pero ya no puedo tocar en dependencias el proyecto como a mi me gustaría. Un compañero mio ha instalado el mismo plugin y no ha podido volver a abrir eclipse. Le da un error en el inicio, antes de abrir nada y de ahí no sale, ni desinstalando el plugin a mano (borrándolo del directorio plugins).
En fin, con eclipse parece que ese plugin no es buena cosa, aunque seguiré en ello.
14 junio 2006
Foro de Java y C++ de Chuidiang
Tengo el foro Foro de Java y C++ de Chuidiang abandonado.
En el trabajo, resulta que tenemos un corta fuegos que no permite acceso a través de un montón de puertos y además el proxy nos prohibe el acceso a determinadas páginas. ¡Sorpresa!. Desde este Lunes está prohibido el acceso al foro (supongo que la prohibición es a foroswebgratis).
En casa, por problemas técnicos que no vienen al caso, estoy sin internet.
Resultado: No puedo ni siquiera ver qué hay en mi propio foro y tampoco puedo actualizar mi página web.
Espero que los problemas técnicos caseros se resulevan pronto....
En el trabajo, resulta que tenemos un corta fuegos que no permite acceso a través de un montón de puertos y además el proxy nos prohibe el acceso a determinadas páginas. ¡Sorpresa!. Desde este Lunes está prohibido el acceso al foro (supongo que la prohibición es a foroswebgratis).
En casa, por problemas técnicos que no vienen al caso, estoy sin internet.
Resultado: No puedo ni siquiera ver qué hay en mi propio foro y tampoco puedo actualizar mi página web.
Espero que los problemas técnicos caseros se resulevan pronto....
Problemas de refresco con internet explorer
Uno de los motivos de mi cabreo con css eran los problemas de refresco que se me plantean en mi página de apuntes de programación cuando se mira con internet explorer.
Si visualizamos la página y ponemos una ventana encima o jugamos con el scroll de una forma "brusca", desaparecen algunas letras o incluso se quedan a medio dibujar.
Jugando ayer, ya tengo una pista del problema. Las líneas que desaparecen es justo encima de los anuncios de google o del buscador de google. Parece entonces que hay algo en los javascript de google que no le gusta al internet explorer. Todavía no he conseguido arreglarlo, pero teniendo la pista ya parece más fácil o, al menos, "ñapeable".
Sin embargo es curioso porque sólo pasa en aquellas páginas que he "modernizado" hace poco con css, dándoles el aspecto de libreta con papel rayado. En las antiguas páginas no pasa. Habrá que seguir investigando un poco.
Si visualizamos la página y ponemos una ventana encima o jugamos con el scroll de una forma "brusca", desaparecen algunas letras o incluso se quedan a medio dibujar.
Jugando ayer, ya tengo una pista del problema. Las líneas que desaparecen es justo encima de los anuncios de google o del buscador de google. Parece entonces que hay algo en los javascript de google que no le gusta al internet explorer. Todavía no he conseguido arreglarlo, pero teniendo la pista ya parece más fácil o, al menos, "ñapeable".
Sin embargo es curioso porque sólo pasa en aquellas páginas que he "modernizado" hace poco con css, dándoles el aspecto de libreta con papel rayado. En las antiguas páginas no pasa. Habrá que seguir investigando un poco.
13 junio 2006
Cascading Style Sheets, Level 2
Dados mis problemas con css, buscando, encotré esto Cascading Style Sheets, Level 2 que supongo que es donde tenía que haber ido desde el principio. Tiene buena pinta salvo que está en un idioma extraño.
Curiosamente, es de la página que me aconsejaba JJR en un comentario de un post anterior.
Curiosamente, es de la página que me aconsejaba JJR en un comentario de un post anterior.
12 junio 2006
Free Java Books
Aunque estén en perfecto inglés, en Free Java Books hay un montón de libros gratis para bajarse sobre java. Están incluidos los de "thinking in java" y "thinking in patterns whith java".
10 junio 2006
Más css
Bueno, acabo de conseguir que se peguen los dos div. El truco es este:
<div>cosas<div>
<div>mas cosas<div>
Si lo hacemos así, sí salen pegados, pero si se nos ocurre hacer esto
<div>cosas</div>
<div><p>mas cosas</p></div>
entonces se separan. Si en vez de <p> es un <h1;> también se separan.
Aparentemente p o h1 tienen un márgen. El div se queda pegadito a la etiqueta p o h1, pero el margen de esa etiqueta cae fuera del div y es lo que hace que se separe del div anterior.
Los contenidos de cada "fila" de pixels serían esto...
div
margen superior de p o h1
otro div y contenido de p o h1
...
Bueno, creo que voy entendiendo cómo va el asunto. A ver si encuentro algún tutorial en castellano que explique cómo son las cosas (la filosofía de css) en vez de limitarse a poner etiquetas explicadas una detrás de otra.
<div>cosas<div>
<div>mas cosas<div>
Si lo hacemos así, sí salen pegados, pero si se nos ocurre hacer esto
<div>cosas</div>
<div><p>mas cosas</p></div>
entonces se separan. Si en vez de <p> es un <h1;> también se separan.
Aparentemente p o h1 tienen un márgen. El div se queda pegadito a la etiqueta p o h1, pero el margen de esa etiqueta cae fuera del div y es lo que hace que se separe del div anterior.
Los contenidos de cada "fila" de pixels serían esto...
div
margen superior de p o h1
otro div y contenido de p o h1
...
Bueno, creo que voy entendiendo cómo va el asunto. A ver si encuentro algún tutorial en castellano que explique cómo son las cosas (la filosofía de css) en vez de limitarse a poner etiquetas explicadas una detrás de otra.
css, internet explorer y firefox una mierda
Bueno, estoy un poco cabreado, así que ahí voy a soltarlo todo.
No tengo ni idea de css, estoy empezando, pero desde luego lo que veo no me gusta nada.
En primer lugar, internet explorer y firefox no se comportan igual ante el mismo código, cada uno hace lo que le da la gana (se supone que firefox hace lo correcto), pero de todas formas hay que andar peleándose para ver si sale igual, o al menos decente, en ambos exploradores y andar "ñapeando" para que así sea.
Luego, con firefox veo cosas que no me cuadran. Intento conseguir que dos div salgan pegados. No hay manera. En algunas de mis páginas sí salen pegados, en otras no y aparentenmente hay lo mismo (ambas incluyen el mismo fichero css y los div están colocados exactamente igual). Seguro que la diferencia es algo que hay dentro del div, pero no logro acertar con qué es. Sin embargo, en el que no lo cosigo, si al div de abajo le pongo un borde solid de 1px entonces misteriosamente se mueve y se pega. Si le pongo 0px vuelve a salir separado. ¿Será que el borde por defecto es de varios pixels? ¿Y si no quiero borde en absoluto? ¿Por qué en otras páginas me sale bien sin necesidad de poner el borde?.
La última mierda: Mi página inicial, por ejemplo, sale bien en internet explorer y firefox, pero me da problemas de refresco en internet explorer. Si se abre una ventana encima y se cierra o se juega con el scroll, desaparecen letras o quedan incluso a medio pintar.
No dudo que con esfuerzo y aprendiendo trucos se puede conseguir que salga bien en todos lados pero ... ¿qué interés tiene para mí echar horas y horas en eso para resolver problemas de los navegadores?.
Voy a seguir un poco más, pero al final creo que pasaré de css y seguiré haciendo mis páginas cutre-simples html y ya. Al final, para poner tutoriales no necesito grandes presentaciones.
No tengo ni idea de css, estoy empezando, pero desde luego lo que veo no me gusta nada.
En primer lugar, internet explorer y firefox no se comportan igual ante el mismo código, cada uno hace lo que le da la gana (se supone que firefox hace lo correcto), pero de todas formas hay que andar peleándose para ver si sale igual, o al menos decente, en ambos exploradores y andar "ñapeando" para que así sea.
Luego, con firefox veo cosas que no me cuadran. Intento conseguir que dos div salgan pegados. No hay manera. En algunas de mis páginas sí salen pegados, en otras no y aparentenmente hay lo mismo (ambas incluyen el mismo fichero css y los div están colocados exactamente igual). Seguro que la diferencia es algo que hay dentro del div, pero no logro acertar con qué es. Sin embargo, en el que no lo cosigo, si al div de abajo le pongo un borde solid de 1px entonces misteriosamente se mueve y se pega. Si le pongo 0px vuelve a salir separado. ¿Será que el borde por defecto es de varios pixels? ¿Y si no quiero borde en absoluto? ¿Por qué en otras páginas me sale bien sin necesidad de poner el borde?.
La última mierda: Mi página inicial, por ejemplo, sale bien en internet explorer y firefox, pero me da problemas de refresco en internet explorer. Si se abre una ventana encima y se cierra o se juega con el scroll, desaparecen letras o quedan incluso a medio pintar.
No dudo que con esfuerzo y aprendiendo trucos se puede conseguir que salga bien en todos lados pero ... ¿qué interés tiene para mí echar horas y horas en eso para resolver problemas de los navegadores?.
Voy a seguir un poco más, pero al final creo que pasaré de css y seguiré haciendo mis páginas cutre-simples html y ya. Al final, para poner tutoriales no necesito grandes presentaciones.
05 junio 2006
PMD y eclipse
PMD es un programa para revisar métricas de nuestro código. Puedes bajártelo como aplicación independiente en http://pmd.sourceforge.net/ y tiene plugings para un montón de IDEs, incluido Maven.
Me bajé la versión 3.1.5 y la instalé con eclipse 3.1.2, pero todo son problemas. Según le das la primera vez para que analize las métricas va bien y saca más métricas no adecuadas de las que me gustaría.
Sin embargo, según voy trabajando y le doy a que repase las métricas, incluso de un sólo fichero, se me queda colgado, tarda un montón y me deja el eclipse más pallá que pacá.
Al final, voy a desinstalar el plugin este y probaré con maven a ver qué tal va...
Me bajé la versión 3.1.5 y la instalé con eclipse 3.1.2, pero todo son problemas. Según le das la primera vez para que analize las métricas va bien y saca más métricas no adecuadas de las que me gustaría.
Sin embargo, según voy trabajando y le doy a que repase las métricas, incluso de un sólo fichero, se me queda colgado, tarda un montón y me deja el eclipse más pallá que pacá.
Al final, voy a desinstalar el plugin este y probaré con maven a ver qué tal va...
Suscribirse a:
Entradas (Atom)

